Last year was crazy for AI music tools; the heavily funded ones ended up getting record deals and their usage has skyrocketed. There is AI slop everywhere now and with music its not different. Apps like Spotify have already been pushing AI music to their listeners for years, and this is only going to get worse. I knew the end of near when Mohini Dey started doing Suno ads! Oh I can all day more about how art being 10xed is the worst thing to happen to the arts in the last century but there are tons of people doing that already without any real regulation in sight; So I want to write about something tangible, something I am personally invested in: How do we reliably detect AI music, and how do we protect human artists and their music from this regurgitated, algorithmic hell slop?
Several independent researchers have developed models for detecting and tagging AI music, which is a great step in the right direction. But the industry keeps evolving, and models can always be engineered to beat this metaphorical Turing test. There are also issues with interpretability and generalization of these AI detection models.
There are tools like HarmonyCloak that claim to make music unlearnable for generative AI models while leaving no perceptible artifacts, but I’ve talked to some people who refute this claim and we also had a friend who tried to use this model to poison our tracks released as a part of Algorave India compilation Album unsuccessfully :( Also HarmonyCloak seems to have started with the MIDI format and does not yet support raw audio formats, as the paper mentions, “The raw audio waveform format can be either converted from the MIDI files using DAWs or recorded from physical instruments.” Bruh what?! And this might be a nitpick, but I was personally never able to run the model locally cause of the massive compute required to add imperceptible adversarial noise. It’s not all bad, though, cause there is potential work yet to be done in this research direction.

Benn Jordan made a couple of cool videos about detecting AI music and poison-pilling music to make it unlearnable with adversarial noise, kind of the same direction: using AI to beat AI. Very related, and I’m also plugging Benn cause his videos are cool.
The most interesting work yet has been from Deezer, which is also ISMIR 2025’s best paper: A Fourier Explanation of AI-Music Artifacts. It’s elegant in a way that I was able to reproduce some of the work in the paper so easily and locally with just my Jupyter notebook, which, these days, is so hard to do without a ton of GPUs at your disposal.
Checkerboard artifact
There was a paper by Google way back in 2016 talking about Deconvolution and Checkerboard Artifacts
A lot of generative tools use deconvolution layers for upsampling the latent representation, and when doing so, pixels sometimes receive more “contributions” from the convolution than others, creating variations in a regular pattern.
For audio, this means that the outputs of generative models will produce small frequency artifacts, i.e., peaks.
This does however depend on the model architecture, and models can always use modified upsampling mechanisms to avoid this irregular kernel overlap.
To reproduce the fingerprint from the paper: I calculate a basic STFT to convert the audio to frequency domain, taking the average spectrum over time with a sliding window and detecting peak values. I also subtract the local minima of the spectrum over the window to highlight the local variations and also remove bandwidth that is of no use (filtering [5-16 kHz]).
This is how the plot looks for a track generated by Suno:
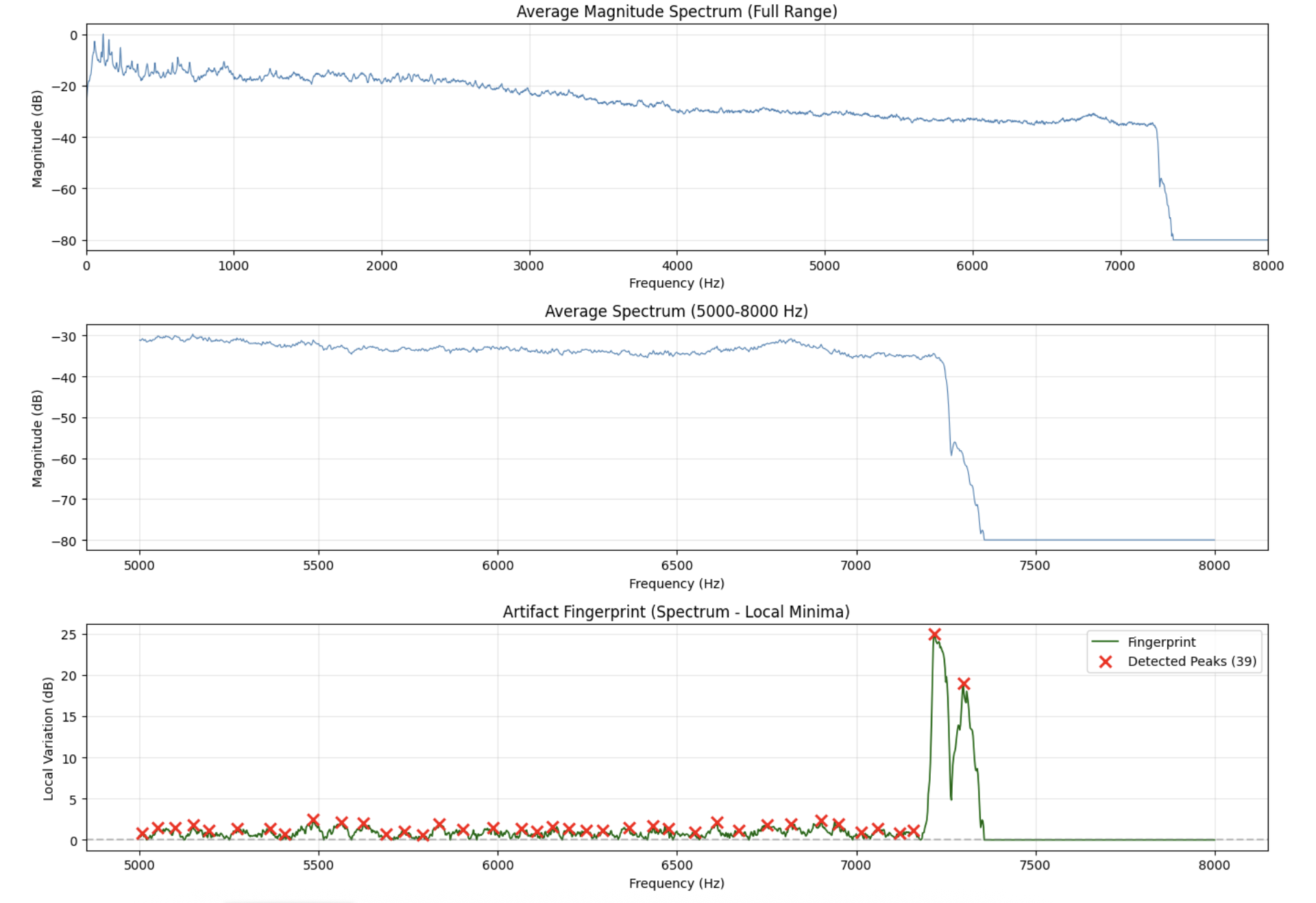
And this is how it looks for “Everything in Its Right Place” by Radiohead:

This is a very specific example but you can see a very clear difference. For the real track, the peaks are relatively uniform and scattered throughout the frequency range and the pattern looks more like natural harmonic content. AI music has a much sharper frequency cutoff and peaks that are more periodic and really stand out.
Once we have these fingerprints, we can easily just train a very simple linear classifier, since different models have different peak patterns we would be able to classify between models as well and technically be able to tell if a track was generated with Suno v2 or Suno v3! Which is pretty fucking cool!
Not to break your bubble but this idea is fully robust, cause even simple audio manipulations like pitch shifting can change the peak frequencies and easily break our classifier. In the future, models could also build around this by using different upsampling techniques to make these artifacts disappear.
But the paper is still important cause it demonstrates something very fundamental: AI music artifacts are not bugs but mathematical certainties given the architecture choice, and you don’t need millions of parameters to detect AI music, sometimes an STFT will do :)
I am still exploring AI poison pill models that are build in a way that is more accessible to independent musicians looking to protect their work! And I really believe working on this with first principles in mind and simpler models would be the way to go. If you are reading this and are interested in similar ideas or know something I’d find interesting plis ping me as I am always available to discuss cool shit. My socials are pasted everywhere on this site.
Ta Ta for now :wq
Leave a Comment