Recently i came across https://www.inkandswitch.com/upwelling/ Upwelling is an exploration of what a text editor might look like if it had both Google-Docs-style real-time collaboration and something like Git-style pull requests.
I thought this was cool but i did not understand anything so i spent the weekend in pursuit of great knowledge which was just me googling shit
So here goes…
For the past few years, we have been hearing the word “asynchronous” and “remote” a lot, there are a shit ton of tools for people to work together and collaborate, starting from google docs to trello, github and figma, we rely on these tools to work with people from different continents, the ability for seamless collaboration has become a major driver in development of tools nowadays rather than an afterthought
To enable this we have collaborative editing algorithms that enable multiple users to edit the same document simultaneously
The goal of these algos is to transmit changes between users with the goal of eventual consistency and if multiple users make changes at the same time their copies of the document might look different for a while, but eventually every user’s view will converge to be the same. But what is that same state ? To do that we need to understand the intent of the users
Operational Transformation
from the early 90s this algorithms is what drives google docs, MS office and lot of huge players offering collaborative editing
Martin Kleppmann has a very nice in a nutshell explanation of OTs here https://youtu.be/PMVBuMK_pJY?t=249
Basically in OT every action taken by user is broken down into one or more operations and are stored with the time and if multiple changes come at the same time OT checks for intent and makes sure the final document reflects the intent of both users and that there is convergence in the end i.e both users see the identical document after execution of all operations
with OT all changes to the document must go thro a single server, google server in the case of docs so we need to be online and we also need to store document changes as a set of operations
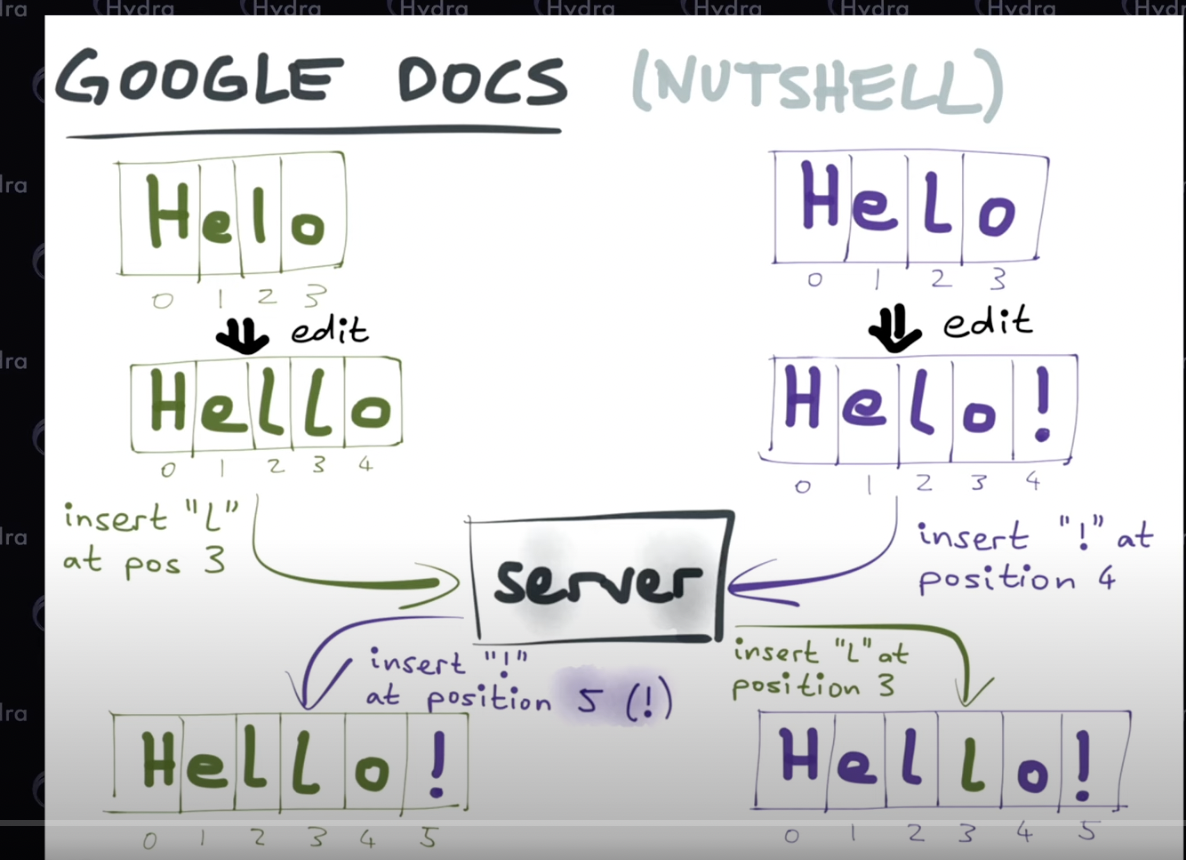
the implementation is also very complex and as seen in the example above simple sync would require the transformation of indexes (why it’s called OT) and deciding the transformation required in case of conflicts and network issues is quite hard
tis explained quite well here: https://medium.com/coinmonks/operational-transformations-as-an-algorithm-for-automatic-conflict-resolution-3bf8920ea447
Conflict-free Replicated Data Type
These are a newer class of algorithms that do not care about the network topology so operations do not have to go thro a single server making it decentralized It is also much easier to understand and implement.
CRDTs are used in systems with optimistic replication, this is where users may modify the data on any replica independently of any other replica, even if the replica is offline or disconnected from the others. We will end up with conflicts and these conflicts then need to be resolved when the replicas communicate with each other.
Let us take a basic example
Alan: The quick fox jumped Bob: The fox jumped over the dog.
When the two users try to sync we need to merge both of their changes. Intuitively, the correct merge result is to keep both of their insertions in the same location, relative to the surrounding text at the time the text was inserted
The quick fox jumped over the dog.
Rather than using indexes for characters like OTs, CRDTs uses an identifier to represent each character
The unique Ids generated here are using clocks/Lamport timestamp as UUIDs which makes sure that one can never create two identical positions, so clocks will never need to be compared
H E L O
[H 0.2] [E 0.4] [L 0.6] [O 0.8]
H E L L O !
[H 0.2] [E 0.4] [L 0.6] [L 0.7] [O 0.8] [! 0.9]
There are cases where the merge decision is not so straightforward because intent is hard
Alice The fox jumped. The fox jumped. Bob The fox jumped.
The word “The” was set to bold by Alice and not changed by Bob, so it should be bold. The word “fox” was set to non-bold by Alice and not changed by Bob, so it should be non-bold. But the word “jumped” was set to non-bold by Alice, and to bold by Bob. In this case we have a conflict on the word “jumped”, because the word cannot be both bold and non-bold at the same time. We, therefore, have to choose arbitrarily between either The fox jumped. OR The fox jumped.
Crucially, even though the choice is arbitrary, it must be consistent across both Alice and Bob’s devices, to ensure they continue seeing the same document state. OT trades complexity for the ability to capture the intent; CRDT has less complexity but can only guarantee all clients end with the same data however that data might not be the intended structure
Concurrent insertion at the same position are interleaved
Hello
Hello Alice! Hello Charlie!
Hello Al Ciharcliee!
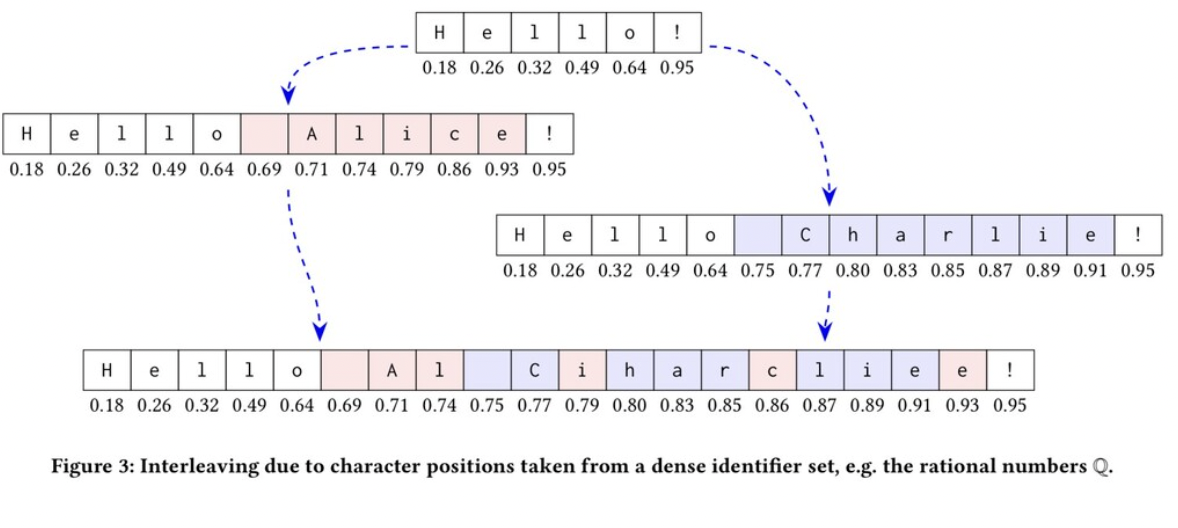
There is a whole paper about interleaving anomalies in collaborative text editors
https://dl.acm.org/doi/10.1145/3301419.3323972 and the above error is just with characters, this gets worse when there are interleaving words or paragraphs i,e in the below example two users insert the word I at the same position
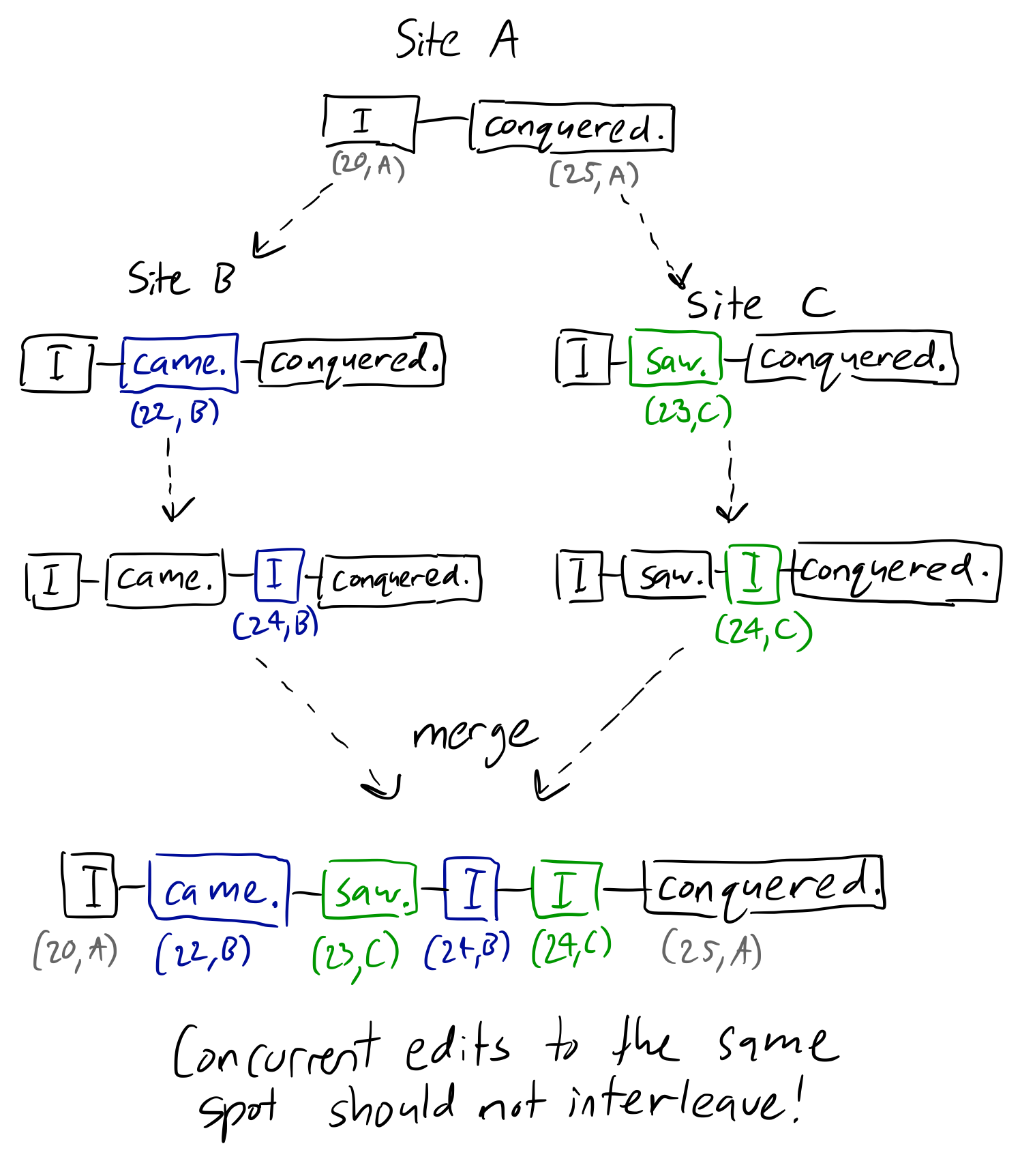
This issue boils down to Intent of the users which becomes hard to ascertain in case of interleaving inserts, most CRDT algorithms have this interleaving issue and the ones that don’t have it like RGA, Treedoc, Woot compromise on performance. RGA (Replicated Growable Arrays) actually is an algorithm that has significantly lesser interleaving anomalies while not compromising a lot by using a deep tree structure. More on it on https://replicated.cc/rdts/rga/ and https://www.bartoszsypytkowski.com/operation-based-crdts-arrays-1/
Moving/ Reordering of List Items when collaborating
A very basic example of this would be a TODO list we are syncing between two users
- Wake up - Wake up - Have chai <-----| Result -> - Suffer in silence - Suffer in silence <--| - Have chai - Sleep - Sleep
Moving items from one index to another to another is not something CRDTs can do natively but they can however do inserts and delete so this Move operation = Insert + Delete
But what is there are conflicts? user A moves have chai to the end and user B moves have chai to the top Then we go the CRDT way we discussed earlier: Arbitrarily but deterministically choose one to the right move
This is similar how a Last Write Wins Register works, this is why registers have become a wide spread way of working with CRDTs The reason is simple: they allow us to wrap any sort of ordinary data types in order to give them CRDT-compliant semantics.
With Last write wins, a timestamp is attached to each update, and updates with higher timestamps always overwrite values written by updates with lower timestamps. However, if a replica has already applied an update with a higher timestamp, and it subsequently receives an update with a lower timestamp, the latter update is ignored. This approach is one way of ensuring convergence.
To construct a CRDT for lists we need a list of Last write wins registers and since we use one register per item list we can put it inside a Add-wins set to ensure movement is possible (Insert + Delete = Move)
Add-wins set (AWSet): In this set additions take precedence over removals. For example, if one user removes and re-adds a TODO element, while another user concurrently removes a TODO, then the merged outcome is that the TODO is in the set. Contrasting to the remove-wins set.
So far CRDTs can help move individual items and lists but generally in a text editor context we operate on a series of elements in one go.
Replica 1 . Bacon \n ----> . Bacon \n . Milk . Soy mMilk \n Replica 2 . Bacon \n <--- Move ----> . Milk \n . Milk \n <--| . Bacon \n Expected convergence 🤗 . Soy milk \n . Bacon \n Actual convergence 😭😭😭 . Milk \n . Bacon \n Soy m
In order to get the expected convergence it is not sufficient to move each element individually: we need to capture the fact that a certain range of elements is moved, so that any concurrent edits that fall within that range can be redirected to the new position of that range.
We also have another issue when implementing move as delete-and-reinsert cause it has the effect of duplicating text if two users concurrently split or join the same bullet point.
At present, there is no known algorithm for performing such moves of ranges of elements. Various tricky edge-cases would need to be handled by such an algorithm, such as concurrent moves of partially overlapping ranges, and moves whose destination position falls within another range that is itself being moved. Part of the solution may be to give each list element a unique identity that is independent from its position in the document, so that the position of a list element can be changed without changing its identity; insertions and deletions can then reference the identities of their context, rather than their position IDs.
Ref Paper: https://dl.acm.org/doi/pdf/10.1145/3380787.3393677
Moving Trees and Subtrees
We have different move operations for tree-based CRDTs, in a simple case where two concurrent moves of the same node happen i,e if we have nodes A,B,C
- User1: Move A to be the child of B
- User2: Move A to be the child of C
then we can take a similar approach to Last Write Wins Register and choose one to win, this particularly helps in trees cause there can be cases where A can be made root by one user and child by another user and you cannot make A a child of its root cause then it becomes a CYCLE NOT A TREE so we need to arbitrarily choose only one of the user’s changes deterministically
ofc we are gonna take an example
Replica 1 [ op1 ] [ op3 ] [ mv A B ] [ op5 ] t=1 t=3 t=4 t=5 Replica 2 [ op2 ] [ mv B A ] [ op7 ] [ op8 ] t=2 t=6 t=7 t=8 Merge the replicas [ op1 ] [ op2 ] [ op3 ] [ mv A B ] [ op5 ] [ mv B A ] [ op7 ] [ op8 ]
So here when we merge we know that replica 2 should discard the t6 operation and to do that we can perform the UNDO operation until we reach t=2 and REAPPLY the operations of Replica 1 till t5 so that the final state or replica 2 is the same as 1 after the first unsafe operation
End Merge
[ op1 ] [ op2 ] [ op3 ] [ mv A B ] [ op5 ]
t=1 t=2 t=3 t=4 t=5
one might think this repeated undo and reapply for merge would be a big overhead but there is not gonna be that many conflicting operations and running tests on it has proved it to be in under a few milliseconds for big scale parallel operations, the worst-case cost of applying a move operation is O(nd) where n is the number of operations in the log that need to be undone and redone, and d is the depth of the tree
Ref: https://martin.kleppmann.com/papers/move-op.pdf
Reducing metadata overhead
One consistent issue we see in CRDTs is the presence of an overhead of metadata, we have a log of unique operations and positions for every character and for all replicas which make up most of the space complexity
A projects that has done major work on compressing CRDT metadata is Automerge https://github.com/automerge/automerge-perf/tree/master/columnar
Automerge uses a columnar encoding for CRDTs that has all necessary metadata
op_id op_type ref value -------- ------- -------- ----- (1,1337) insert null 'h' (6,d00d) delete (1,1337) (7,d00d) insert null 'H' (2,1337) insert (1,1337) 'e' (3,1337) insert (2,1337) 'l' (4,1337) insert (3,1337) 'l' (5,1337) insert (4,1337) 'o'
Each operation has a unique ID that is a pair of (counter,actorId) where actorId is the unique name that generates the operation. In the example above, 1337 and d00d are actorIds.
Each operation also references the ID of another operation (the ref column)
- for an insert operation, the reference is the ID of the predecessor character
- for a delete operation, the reference is the ID of the character being deleted.
For insert operations, the reference may be null, indicating an insertion at the beginning of the document.
Thus, the operation history above represents actor 1337 typing the word hello, followed by actor d00d deleting the initial lowercase h and replacing it with an uppercase H.
Order of operations in this table is arbitrary. So we can put the operations in whatever order we like and choose an order that will give us an efficient encoding.
- Counter we can sort the counter to be
1,2,3,4,5and then store the difference between the characters i,e delta encode =(5, 1)so we count till 5 with a delta of 1 which can be stored in 2 bytes - Actors We can group by actors and make a lookup table
{1337: 0, d00d: 1}which makes the column a number sequence[0, 1, 1, 0, 0, 0, 0]that can be Run length encoded[1, 2, 4] - Op_ID same groupby followed by Run length encoding can be done for op_ids
- Value Here the deletion operation doesn’t has a value so our sequence for this column will only contain six values, while the other sequences contain seven values. Next, we construct a sequence of numbers indicating how many bytes are required to represent each of the values in an UTF-8 encoding; in the example, this is [1, 1, 1, 1, 1, 1], which RLE handles great. Finally, we can store a string that is the concatenation of all of the UTF-8 values: ‘hHello’ in this example.
This idea of column-oriented or columnar encoding is quite well established in analytic databases such as data warehouses and is not something new
Caveat These compression benefits only kick in because we are encoding the entire document in one go. If every change is encoded separately with only a small number operations per change the compression will be less effective. Depending on the editing patterns of a document, it might in some situations be more efficient to send the entire document (encoded and compressed as a whole) rather than a log of individually encoded changes. We can still merge two entire documents, since each of them internally is just a set of operations, of which we can take the union.
Automerge introduced this encoding and compression to CRDTs so we have all historical state and ability to reconstruct the final state, very cool!
Logoot
There are tons of CRDT implementations: Logoot, LSEQ, RGA, Treedoc, WOOT etc…
Logoot is one of the easier CRDTs to understand, and extensions/variations have also been built upon it to enable extra functionality, like group undo/redo
It is based on the idea of assigning unique identifiers to each character in the document and using these identifiers to track changes made by different users and performs the insertions and deletions based on the position of these identifiers.
In Logoot, the document is split up into groups of text. A group of text is called an atom. Each atom is given a unique identifier, or a uid, which has to be generated in a special way that will be covered later. Each uid is comparable to other uids. This means that you can do things like ask if uid1 < uid2, and vice versa. You can also check if they are equal. The document is then stored as an array of (uid, atom) pairs, sorted by the uids within the pairs in ascending order. There will also be two special, blank lines that exist in every document. One at the very start which will have the MIN_uid, and at the very bottom, which will have the MAX_uid.
Phew, that was a lot to take in. Here comes the most important part though. For any two different uids, you should always be able to find a uid in between them. This is the property that makes Logoot work. So, the uids in Logoot need to be represented in a way that adheres to the property.
https://hal.inria.fr/inria-00432368/document
Differential Synchronization
DS is an algorithm that is used to synchronize changes between two copies of a document. It works by identifying the differences between two versions of a document and sending only the changes between them. This helps editing over low-bandwidth connections
But the thing is diff-match-patch algorithms aren’t usually not stable / reliable in the face of conflicts. Diffing is also expensive and unnecessary if you know what changes you’re making to the data structure anyway.
The key feature of DS is that it is simple and well suited for use in both novel and existing state-based applications without requiring application redesign which is necessary when we want to use CRDTs or OTs
https://neil.fraser.name/writing/sync/
material i stole from
- https://www.youtube.com/watch?v=PMVBuMK_pJY
- CRDT Glossary https://crdt.tech/glossary
- https://www.inkandswitch.com/peritext/
- https://doc.akka.io/docs/akka/2.6.3/typed/distributed-data.html#replicated-data-types
- https://www.tiny.cloud/blog/real-time-collaboration-ot-vs-crdt/
- https://medium.com/@ravernkoh/collaborative-text-editing-with-logoot-a632735f731f
- https://josephg.com/blog/crdts-are-the-future/
Leave a Comment