Understandable Consensus Algorithm: Raft
Material
- Paper: http://nil.csail.mit.edu/6.824/2020/papers/raft-extended.pdf
- FAQ: http://nil.csail.mit.edu/6.824/2020/papers/raft-faq.txt & http://nil.csail.mit.edu/6.824/2020/papers/raft2-faq.txt
- Visual Aid: http://thesecretlivesofdata.com/raft/
- Site: https://raft.github.io/
- Videos: https://www.youtube.com/watch?v=64Zp3tzNbpE & https://www.youtube.com/watch?v=4r8Mz3MMivY
- RC notes: https://docs.google.com/document/d/1ElFUjssB2sp6vlzoakO9QQEbev_Bl2_XfmrM_uK2WHI
So far with systems like GFS we had one master and it handled operations across distributed systems but as more complicates systems rose having one master became the bottleneck and even when we have multiple masters we need a good consensus algorithm that allows a collection of machines to work as a coherent group that can survive the failures of some of its members.
Paxos was the earliest and a very popular algorithm for consensus. This paper paints Paxos as a scary algorithm that is very very hard to understand, work with and build practical implementations. To mitigate this Raft was developed with a focus on understandability rather than anything else
- Strong Leader i.e Logs only flow from leader to other servers simplifying replicated log management
- Random Timers to Elect Leaders small mechanism on top of existing heartbeats helps resolving conflicts simply and rapidly
- Joint Consensus for Membership Changes allows majority of the two different configurations to overlap during transitions. This allows the cluster to continue operating normally during configuration changes.

Replicated state machines
A collection of servers compute identical copies of the same state and can continue operating even if some of the servers are down to provide fault tolerance.
Replicated state machines are typically implemented using a replicated log containing a series of commands, which its state machine executes in order.
Keeping the replicated log consistent is the job of the consensus algorithm.
The consensus module on a server receives commands from clients and adds them to its log and also ensures that every server has the same logs in the same order even if some servers fail. Some practical rules followed by consensus algorithms.
- They never return incorrect results even in bad conditions like network delays, packet loss, duplication and reordering
- They are fully functional as long as any majority of the servers are operational and can communicate with each other and with clients (eg: 3 out of 5)
- Independent of timing for consistency so as to tolerate faulty clocks and extreme message delays.
In a RAFT system of 2K+1 machines we can tolerate K failures eg: 3 machines we can tolerate 1 failure
The Algorithm
Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply log entries to their state machines. Having a leader simplifies the management of the replicated log. For example, the leader can decide where to place new entries in the log without consulting other servers, and data flows in a simple fashion from the leader to other servers. A leader can fail or be-come disconnected from the other servers, in which case a new leader is elected.
The leader waits until a majority of nodes have written the entry to the log before making changes to the state machine
A Raft cluster contains several servers; five is a typical number, which allows the system to tolerate two failures. At any given time each server is in one of three states: leader, follower, or candidate
- In normal operation there is exactly one leader and all of the other servers are followers.
- Followers are passive: they issue no requests on their own but simply respond to requests from leaders and candidates.
- The leader handles all client requests so if a client contacts a follower, the follower redirects it to the leader
- The third state candidate is used to elect a new leader
Raft divides time into terms of arbitrary length called terms, each term begins with an election where candidates attempt to become leader for the rest of the term, In a split vote no leader is elected and a new term will start shortly.
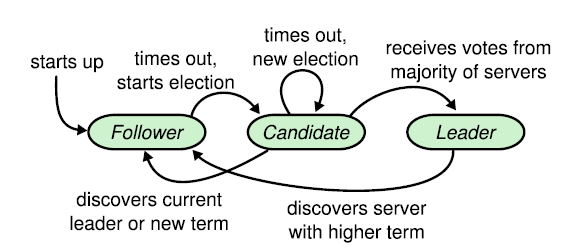
- Different servers may observe the transitions between terms at different times, and in some situations a server may not observe an election or even entire terms.
- Terms act as a logical clock in Raft, and they allow servers to detect obsolete information such as stale leaders.
- Each server stores a current term number, which increases monotonically over time.
- Current terms are exchanged whenever servers communicate; if one server’s current term is smaller than the other’s, then it updates its current term to the larger value. If a candidate or leader discovers that its term is out of date, it immediately reverts to follower state. If a server receives a request with a stale term number, it rejects the request.
Raft servers communicate using remote procedure calls (RPCs) and the basic consensus algorithm requires only two types of RPCs. RequestVote RPCs are initiated by candidates during elections and Append Entries RPCs are initiated by leaders to replicate log entries and to provide a form of heartbeat
Raft Guarantees / Commandments
- Election Safety: at most one leader can be elected in a given term.
- Leader Append-Only: a leader never overwrites or deletes entries in its log; it only appends new entries
- Log Matching: if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.
- Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
- State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
Leader Election
- All our nodes start in the follower state
- If followers don’t hear the periodic
heartbeats i.e
AppendEntriesRPCs that carry no log entries from a leader then the follower assumed no leader exists and can become a candidate (Election timeout) - The candidate then requests votes from other nodes in parallel using the RequestVote RPCs
Now based on the votes 3 things can happen
Candidate Wins Election If it receives votes from a majority of the servers and on winning sends heartbeat messages to all of the other servers to establish its authority and prevent new elections.
Another Server Claims leadership when the candidate receives an heartbeat RPC from the so called “leader” now it checks if the leader’s term (counter) is at least as large as the candidate’s current term and if it is then it recognizes the leader and goes back to follower else it rejects the RPC and continues the election.
No Winner happens incases of Split votes and no majorities, when a lot of followers become candidates at the same time. When this happens, each candidate will time out and start a new election by incrementing its term and initiating another round of Request- Vote RPCs. However, without extra measures split votes could repeat indefinitely
Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly
An election term will continue until a follower stops receiving heartbeats and becomes a candidate.
Log Replication
Once a leader has been elected, it begins servicing client requests. Each client request contains a command to be executed by the replicated state machines.
The leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry. When the entry has been safely replicated the leader applies the entry to its state machine and returns the result of that execution to the client. If followers crash or run slowly or if network packets are lost, the leader retries AppendEntries RPCs indefinitely even after it has responded to the client until all followers eventually store consistent log entries.
The leader decides when it is safe to apply a log entry to the state machines; such an entry is called committed. Raft guarantees that committed entries are durable and will eventually be executed by all of the available state machines. The leader keeps track of the highest index it knows to be committed, and it includes that index in future AppendEntries RPCs (including heartbeats) so that the other servers eventually find out.
Raft maintains the following properties to maintain coherency between the logs on different servers.
- If two entries in different logs have the same index and term, then they store the same command
- If two entries in different logs have the same index and term, then the logs are identical in all preceding entries
This consistency check acts as an induction step: the initial empty state of the logs satisfies the Log Matching Property, and the consistency check preserves this property whenever logs are extended. As a result, whenever AppendEntries returns successfully, the leader knows that the follower’s log is identical to its own log up through the new entries.
In Raft, the leader handles inconsistencies by forcing the followers logs to duplicate its own. This means that conflicting entries in follower logs will be overwritten with entries from the leaders log.
The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower. When a leader first comes to power it initializes all nextIndex values to the index just after the last one in its log.If a follower’s log is inconsistent with the leaders the AppendEntries consistency check will fail. After a rejection, the leader decrements nextIndex and retries AppendEntries RPC. Eventually nextIndex will reach a point where the leader and follower logs match. When this happens, AppendEntries will succeed, which removes conflicting entries in the followers log and appends entries from the leaders log. Once AppendEntries succeeds, the follower’s log is consistent with the leaders for the rest of the term.
Once AppendEntries succeeds, the follower’s log is consistent with the leader’s, and it will remain that way for the rest of the term.
Along with logs we also need to persist
- Current Term Servers can crash and come up at any time and if you look the case in the next section S2 should have a persistent record of Current term so that it can initialize to term 8 otherwise there finna be chaos
- VotedFor A Server votes then crashes and comes up again in the same term to vote again which means two votes for the same term ? Nahh can’t happen which is is why VotedFor should also be Persistent so that crashed server knows its already voted for that term
Election Restriction
How would a server cast its vote during an election, can we just choose the server with the longest log ?
S1 5 6 7
S2 5 8
S3 5 8
- S1 gets elected as leader for term 6 after receiving majority votes, receives a client request and crashes before sending out the append entries
- S1 comes back up gets elected for term 7 and does the same thing where it gets an entry appends to its log and before sending it out to other servers crashes again
- Now S2 gets elected for term 8 (Even tho S1 went down before going down won the election by soliciting votes from majority of servers by sending its election term number(7) hence majority servers know that the next term is 8)
- If S2 goes down and another election happens even tho S1 has more logs its redundant and hence must be re-written
Here are the Election Restrictions: As F Vote Yes to server S soliciting votes Only If
1) S Has a Higher term in the last entry then F 2) The last term is the same but S has a longer or the same log length as F
Now if S1 logs are rewritten the rewinding one by one with the leader logs will be a pain in the ass, so instead we use the term number to skip ahead to the last term when the leader and the lagging follower were similar and replace all logs from there one out to make similar to leader again
Safety
Ensures that the state machine executes exactly the same commands in the same order.
This is called Linearizability and it implies that every operation appears to take place atomically, in some order, consistent with the real-time ordering of those operations
This rule might be broken if a follower might goes down while the leader commits several log entries, then it could be elected leader and overwrite these entries with new ones, as a result different state machines might execute different command sequences.
So now do we ensure safety when a leader or one of the followers crashes ?
Leader Crashes
Raft handles inconsistencies by forcing the followers log to duplicate the leaders, meaning that conflicting entries in a followers log can be overwritten by the entries in the leaders log. To make the logs between a leader and follower consistent, the leader first finds the latest index at which their logs are identical, deletes all the entries in the followers log after that index, and then sends the follower the entries in its own log that come after that point.
When can a new leader to overwrite its followers logs?
This can be avoided with a simple rule called Leader Completeness which ensures that the leader for any given term contains all of the entries committed in previous terms
The leader for any given term contains all of the entries committed in previous terms
Raft guarantees that all the committed entries from previous terms are present on each new leader from the moment of its election, without the need to transfer those entries to the leader. This means that log entries only flow in one direction, from leaders to followers, and leaders never overwrite existing entries in their logs.
Raft prevent a candidate from winning an election unless its log contains all committed entries. The Candidates log has to be atleast as up-to-date with any other log in the majority where up-to-date: If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
By this restriction, it is safe for a leader to overwrite a followers log since the leader will always have the latest committed entries. Any uncommitted entries can be safely discarded because there is no expectation on the clients side that their request has been executed. Only committed entries guarantee that. Therefore, the server can return an error message to the client, telling it to retry the requests for the uncommitted entries.
- Client sends a Request to execute
SET a 10 - Leader appends it to the logs and sends it to all followers which also append it to their logs
- Before the leader can send out the RPC to execute the logs it crashes
- The client gets an error message :(
- Now when the new leader comes up it sees the log
SET a 10in the majority of the servers - Raft never commits log entries from previous terms by counting replicas it is only done for the leaders current term
- So the
SET a 10log is discarded even tho its on majority on servers
There are some situations where a leader could safely conclude that an older log entry is committed (for example, if that entry is stored on every server), but Raft takes a more conservative approach for simplicity.
Follower Crashes
If a follower crashes then future RPCs sent to it will fail. Raft handles these failures by retrying indefinitely if the crashed server restarts then the RPC will complete successfully and since Raft RPCs are idempotent this causes no harm i.e if a follower receives an AppendEntries request that includes log entries already present in its log, it ignores those entries in the new request.

When the leader at the top comes to power, it is possible that any of scenarios (a–f) could occur in follower logs. Each box represents one log entry; the number in the box is its term. A follower may be missing entries (a–b), may have extra uncommitted entries (c–d), or both (e–f). For example, scenario (f) could occur if that server was the leader for term 2, added several entries to its log, then crashed before committing any of them; it restarted quickly, became leader for term 3, and added a few more entries to its log; before any of the entries in either term 2 or term 3 were committed, the server crashed again and remained down for several terms

Raft never commits log entries from previous terms by counting replicas which means we never commits log entries from previous terms, let see what will happen again at figure 8. I modified figure 8 to show the situation after apply the rule.
(a) and (b) works the same. Start from (c), log entry at index 2 is append at term 2 since step (a), where I draw a yellow circle. So it is from previous terms. Thus the leader will not replicate that entry (the yellow 2 with my black cross) according the rule. It must start replicate from entry at index 3. Since we also Send AppendEntries RPC with entries starting at nextIndex.
The nextIndex is initialized with last log index + 1, so it should start at log index 3 at (c), not index 2.
So for the hypothetical procedure at original (c), it is impossible to append log 2 to majority before log 3(the pink one appended at term 4) replicate at majority. and (d) will not happen.
A time sequence showing why a leader cannot determine commitment using log entries from older terms. In (a) S1 is leader and partially replicates the log entry at index
- In (b) S1 crashes; S5 is elected leader for term 3 with votes from S3, S4, and itself, and accepts a different entry at log index 2. In (c) S5 crashes; S1 restarts, is elected leader, and continues replication. At this point, the log entry from term 2 has been replicated on a majority of the servers, but it is not committed. If S1 crashes as in (d), S5 could be elected leader (with votes from S2, S3, and S4) and overwrite the entry with its own entry from term 3. However, if S1 replicates an entry from its current term on a majority of the servers before crashing, as in (e), then this entry is committed (S5 cannot win an election). At this point all preceding entries in the log are committed as well.
Timing and availability
broadcastTime ≪ electionTimeout ≪ MTBF
- broadcastTime is the average time it takes a server to send RPCs in parallel to every server in the cluster and receive their responses;
- electionTimeout is the randomized election timer in follower that makes it a candidate and triggers an election
- MTBF (mean time between failures) is the average time between failures for a single server.
Since broadcast time may range from 0.5ms to 20ms, depending on storage technology, The election timeout is likely to be somewhere between 10ms and 500ms.
Suppose the randomized election timeouts lie between Tmin and Tmax then Tmin must be atleast double of heartbeat team cause we don’t want hella elections to be happening even before a heartbeats go out. Tmax is the max time we can afford our system to be down cause when a leader is down and the next election hasn’t happened the whole system is frozen so Tmax or the max value of the randomized election timeout cannot be too high, depends on how often failures happen and how available we want the system to be. It also cannot be too low cause between on a random election timeout servers need time to cast votes and elect a leader before the next timeout.
Log compaction
To prevent the log from growing indefinitely, which can increase the time it takes for the state machine to replay a log when it restarts, Raft uses snapshotting for log compaction. A snapshot of the current applications state is written to durable storage, and all the log entries up to the point of the snapshot are deleted from the log. Each server takes its snapshots independently, and snapshots are taken when the log reaches a fixed size in bytes.
A snapshot also contains metadata such as the last included index, which is the index of the last entry in the log being replaced by the snapshot, and the last included term. These metadata are kept because of the AppendEntries consistency check for the first log entry after the snapshot, which needs a previous log entry and term.
End notes & Questions
RAFT can fail when a leader can send out outgoing requests i.e heartbeats but cannot accept incoming requests i.e from the client. In these case even tho leader fails to serve the client the followers get the heartbeat and assume everting is ok. A way to solve this is to also send a response from the follower to the leader heartbeat which needs to be acknowledged, this way we can catch situations where leader doesn’t respond to incoming requests and re-trigger an election.