Cloud Replicated DB: Aurora
Paper http://nil.csail.mit.edu/6.824/2020/papers/aurora.pdf
Lecture https://www.youtube.com/watch?v=jJSh54J1s5o
History
The very first and one of the most successful offerings amazon came up with as AWS EC2 instances which are a bunch of Virtual Machines running an OS connected to a Hard drive and managed by a Virtual Machine Manager at AWS data centers. This was ideal for webservers cause it was easy to quickly spin one up and just spin multiple if we needed to scale, Now databases were also hosted on these EC2 machines but had a caveat. With webservers being stateless when the VM or disk crashed we could just spin up another one and continue work but with Databases being stateful disk failures ended could be catastrophic
This led to periodic snapshots to database and backing it up to S3 where it could be recovered and restored on crash but even then we kinda lose the data in between snapshots
AWS now came up with another offering called EBS which is made up of a set of chain replicated storage volumes and with this EC2 instances running databases would mount an EBS volume and when shit goes south it can remount it back up again to retain all the data. So EBS was awesome for managing state but EBS volume can only be mounted by one EC2 at a time, its not sharable also it amplified the network traffic cause of the writes to the DB happens on a NFS and on a setup with frequent writes this could be a bottleneck. This meant that for EBS to work without major network throttles they had to place all the replicas in the same data center/ availability zone.
Then amazon came up with RDS with an attempt to replicate the data across different Availability Zones so it essentially had a main database mounted with an EFS which upon getting a write sends it across to replica across the world which writes those records to its EBS volume and becomes a mirror, so this was fault tolerant but its again bottlenecked by the huge amount of data that has to be shared across the network to different availability zones. Writes to databases are also amplified cause of the architecture of databases wherein it organizes its records into pages. When a page in the database is about to be updated, the page is first retrieved from disk and stored in a page cache in memory. The changes are then made against that cached page until it is eventually synchronized with the persistent storage. A cached page is said to be dirty when it has been updated in memory and it needs to be flushed back on disk
Introduction
Amazon Aurora is a relational database service for OLTP workloads
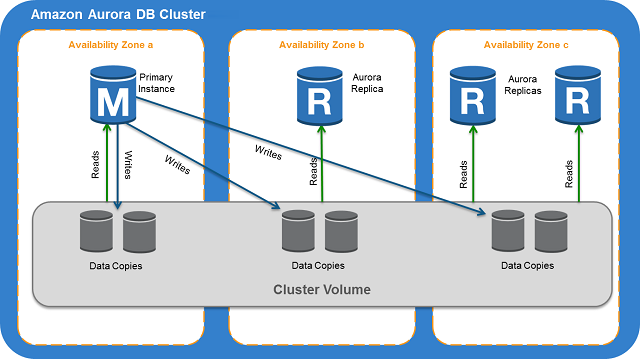
It also brought with it storage across availability zones for fault tolerance but instead of writing the logs and updating the page in the btree index and the DB for each replica it just wrote the logs entries thus significantly reducing network load which meant that the underlying storage could not be a dumb ebs volume but something that knew what to do with the transactional logs
- Only write logs to replicas across AZones to reduce network IOs
- Since we offload log processing to the storage service it should be Application Specific instead of general purpose
The log is the database
Here is how a traditional database like Postgres works
- A system like MySQL writes data pages to objects it exposes heap files, b-trees etc as well as redo log records to a write-ahead log (WAL) which is durably persisted to disk
- Each redo log record consists of the difference between the after-image and the before-image of the page that was modified and can be applied to the before-image of the page to produce its after-image
- When DB crashes with the data pages still in-memory as btree or heaps we kinda lose that data and in these situations write-ahead log helps with recovery by ensuring that the database can still apply the logged changes to the on-disk structure.
- If the DB does not crash then the in-memory pages are written to disk after crossing a certain size ( In Btrees )
Aurora decouples the storage layer
When a traditional database modifies a data page, it generates a redo log record and invokes a log applicator that applies the redo log record to the in-memory before-image of the page to produce its after-image.
But in Aurora the only writes that cross the network are redo log records which are rather small. No pages are ever written from the database tier, not for background writes, not for checkpointing, and not for cache eviction. Instead, the log applicator is pushed to the storage tier where it can be used to generate database pages in background or on demand.
The log applicator is still present at the database layer. This way we can still modify cached data pages based on the redo log records and read up-to-date values from them. The difference now is that those dirty pages are not written back to the storage layer instead, only the log records are written back.
Performance
For greater Performance even though Aurora has 6 storage servers across 3 availability zones and since one can expect some slow servers aurora does not expect answers from all storage servers in order o process a log but instead uses a Quorum Writes and only cares about responses from 4 out of the 6 servers / majority
Here are some of the fault tolerance goals aurora set out to fulfil for the storage server
- Write even when one Availability Zone (AZ) is fully dead
- Read with 1 dead AZ + 1 dead server
- Keep going even when some servers are temporarily suffering from slow network
- Fast re-replication so the servers can be back at it again much faster
Quorums
| Write to all N servers and only W have to respond | Read from all N servers and wait for R to respond |
R + W = N + 1 In aurora N=4 W=4 R=3
Read Quorums use Version Number to make sure it reads the latest data
In Aurora the database server sends the log records to the storage nodes and keeps track of the progress of each segment in its runtime state. Which means the main database layer knows which storage server is the most up to date. Therefore, under normal circumstances the database layer can issue a read request directly to the segment which has the most up-to-date data without needing to establish a read quorum.
However after a crash the database server needs to reestablish its runtime state through a read quorum of the segments for each protection group.
During recovery after the database server crashes and is restarted, Aurora has to make sure that it starts with a complete log. The potential problem is that there might be holes in the sequence of log entries near the end of the log, if the old database server wasn’t able to get them replicated on the storage servers. The recovery software scans the log (perhaps with quorum reads) to find the highest LSN for which every log entry up to that point is present on a storage server which is called VCL. It tells the storage servers to delete all log entries after the VCL. That is guaranteed not to include any log entries from committed transactions, since no transaction commits (replies to the client) until all log entries up through the end of the transaction are in a write-quorum of storage servers
LSN: log sequence number
Find out update entries in the log that don’t have commit record and issue Undo operations which is why logs have Old entries and New entries { "old":10, "new":15, "op":"update" }
In Aurora, the database tier can have up to 15 read replicas and one write replica. Having one writer makes it easy maintaining numbered records. In addition to the storage nodes, the log stream generated by the writer is also sent to the read replicas. The writer does not wait for an acknowledgement from the read replicas before committing a write, it only needs a quorum from the storage nodes. Each read replica consumes the log stream and uses its log applicator to modify the pages in its cache based on the log records. By doing this, the replica can serve pages from its buffer cache and will only make a storage IO request if the requested page is not in its cache.
We designed Aurora as a high throughput OLTP database that compromises neither availability nor durability in a cloud-scale environment. The big idea was to move away from the monolithic architecture of traditional databases and decouple storage from compute. In particular, we moved the lower quarter of the database kernel to an independent scalable and distributed service that managed logging and storage. With all I/Os written over the network, our fundamental constraint is now the network. As a result we need to focus on techniques that relieve the network and improve throughput. We rely on quorum models that can handle the complex and correlated failures that occur in large-scale cloud environments and avoid outlier performance penalties, log processing to reduce the aggregate I/O burden, and asynchronous consensus to eliminate chatty and expensive multi-phase synchronization protocols, offline crash recovery, and checkpointing in distributed storage. Our approach has led to a simplified architecture with reduced complexity that is easy to scale as well as a foundation for future advances.
Aurora vs Google Spanner
The main pragmatic difference is that Aurora is limited to just one read/write database server. If you have more read/write transactions than can be handled with a single server, Aurora alone won’t be good enough. Spanner, in contrast, has a pretty natural scaling story, since it not only shards its data, but also can run transactions that affect different shards entirely independently.
They share three important attitudes. First, they both view having replicas in multiple independent datacenters to be important, to ensure availability even if an entire datacenter goes offline. Second, they both use quorum writes to be able to smoothly tolerate a minority of unreachable or slow replicas (and this is partially to tolerate offline datacenters). Third, they both support high read throughput (Spanner with its time-based consistent reads, and Aurora with its read-only database replicas).
A huge difference is that Aurora is a single-writer system – only the one database on one machine does any writing. This allows a number of simplifications, for example there’s only one source of log sequence numbers. In contrast, Spanner can support multiple writers (sources of transactions); it has a distributed transaction and locking system (involving two-phase commit).
A murky aspect of Aurora is how it deals with failure or partition of the main database server. Somehow the system has to cut over to a different server, while ruling out the possibility of split brain. The paper doesn’t say how that works. Spanner’s use of Paxos, and avoidance of anything like a single DB server, makes Spanner a little more clearly able to avoid split brain while automatically recovering from failure.