Wait-free coordination: Zookeeper
- Paper http://nil.csail.mit.edu/6.824/2020/papers/zookeeper.pdf
- Notes https://timilearning.com/posts/mit-6.824/lecture-8-zookeeper/
ZooKeeper is a service for coordinating processes of distributed applications, it is built for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Linearizability and Guarantees
In distributed systems like RAFT master handles all the traffic and scaling up the number of servers won’t really scale up the performance since leader is the bottleneck and leader has more replicas to handle and while this bottlneck is needed to keep things to be linearizable Zookeeper prefers higher read performance and hence lets you query from the replicas that are not master directly by sacrificing linearity which means you could read stale data. But Writes are linearizable
This does not mean ZK has no guarantees at all, it provides a FIFO execution order at the client level which means for a every client reads and writes are executed in the same order they are sent and the current read will see the previous write BUT if the previous write is from a different client then zookeeper cannot guarantee the current read is the latest
Introduction
ZK is compared to Chubby in a lot of places, chubby is a lock service for loosely-coupled distributed systems built by Google
Group membership, Configuration and leader elections are common forms of coordination in distributed systems, we also want our processes to know which other processes are alive and what those processes are in charge of.
Locks constitute a powerful coordination primitive that implement mutually exclusive access to critical resources but Zookeeper moved away from locks cause its blocking and hence can cause slow or faulty clients to negatively impact the performance of faster clients.
Zookeeper has the following properties
- Wait Free (Performance ++)
- FIFO Client Ordering (all requests from a given client are executed in the order that they were sent by the client.)
- Linearizable writes (all requests that update the state of ZooKeeper are serializable and respect precedence)
Guaranteeing FIFO client order enables clients to submit operations asynchronously and when this happens we also have to make sure they are Linearizable which has a performance cost

For this we implement a leader-based atomic broadcast protocol called ZAB (Zookeeper Atomic Broadcast) which is a consensus protocol similar to Raft or Paxos. More Info
Zookeeper is read heavy so client side caching is important so it allows clients to cache and watch for updates to the cached object and receive a notification. Chubby uses leases to avoid blocking from faulty clients
By implementing these watches zookeeper allow clients to receive timely notifications of changes without requiring polling.
- Coordination Kernel proposes a wait-free coordination service with relaxed consistency guarantees for use in distributed systems.
- Use Coordination recipes to build higher level coordination primitives, even blocking and strongly consistent primitives that are often used in distributed applications
Terminology
We use client to denote a user of the ZooKeeper service, server to denote a process providing the ZooKeeper service, and znode to denote an in-memory data node in the ZooKeeper data, which is organized in a hierarchical namespace referred to as the data tree. We also use the terms update and write to refer to any operation that modifies the state of the data tree. Clients establish a session when they connect to ZooKeeper and obtain a session handle through which they issue requests.
The znodes in this hierarchy are data objects that clients manipulate through the ZooKeeper API. Hierarchical name spaces are commonly used in filesystems. It is a desirable way of organizing data objects since users are used to this abstraction and it enables better organization of application metadata.
we use the standard UNIX notation for file system paths. For example, we use /A/B/C to denote the path to znode C, where C has B as its parent and B has A as its parent.
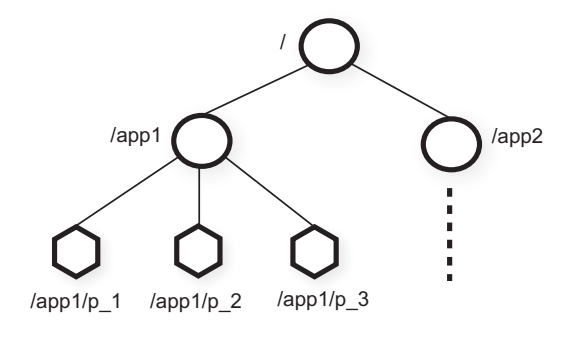
znodes map to abstractions of the client application, typically corresponding to meta-data used for coordination purposes.
we have two subtrees, one for Application 1 (/app1) and another for Application 2 (/app2). The subtree for Application 1 implements a simple group membership protocol: each client process p i creates a znode p i under /app1, which persists as long as the process is running.
Note that although znodes are not designed for general data storage, they allow clients to store specific metadata or configuration. For example, it is useful for a new server in a leader-based system to learn about which other server is the current leader. To achieve this, the current leader can be configured to write this information in a known znode space. Any new servers can then read from that znode space.
There is also some metadata associated with znodes by default like timestamps and version counters, with which clients can execute conditional updates based on the version of the znode
A client can create two types of znodes:
- Regular: Regular znodes are created and deleted explicitly.
- Ephemeral: Ephemeral znodes can either be deleted explicitly or are automatically removed by the system when the session that created them is terminated.
All znodes store data and all znodes except for ephemeral znodes can have children and Additionally, when creating a new znode, a client can set a sequential flag. Nodes created with the sequential flag set have the value of a monotonically increasing counter appended to its name. If n is the new znode and p is the parent znode, then the sequence value of n is never smaller than the value in the name of any other sequential znode ever created under p.
When a client issues a read operation with a watch flag set, the operation completes as normal except that the server promises to notify the client when the information returned has changed. Watches are one-time triggers associated with a session; they are unregistered once triggered or the session closes. Watches indicate that a change has happened, but do not provide the change which means Session events, such as connection loss events, are also sent to watch callbacks so that clients know that watch events may be delayed.
Client API
The ZooKeeper client API exposes a number of methods.
-
create(path, data, flags): Creates a znode with pathname path, stores data[] in it, and returns the name of the new znode. flags enables a client to select the type of znode: regular, ephemeral and set the sequential flag
-
delete(path, version): Deletes the znode path if that znode is at the expected version;
-
exists(path, watch): Returns true if the znode with path name path exists, and returns false otherwise. The watch flag enables a client to set a watch on the znode;
-
getData(path, watch): Returns the data and meta-data, such as version information, associated with the znode. The watch flag works in the same way as it does for exists(), except that ZooKeeper does not set the watch if the znode does not exist;
-
setData(path, data, version): Writes data[] to znode path if the version number is the current version of the znode;
-
getChildren(path, watch): Returns the set of names of the children of a znode;
-
sync(path): Waits for all updates pending at the start of the operation to propagate to the server that the client is connected to. Sync can ensure that the read for a znode is linearizable though it comes at a performance cost. It forces a server to apply all its pending write requests before processing a read. Similar to FLUSH primitive
All methods have both a synchronous and an asynchronous version available through the API. An application uses the synchronous API when it needs to execute a single ZooKeeper operation and it has no concurrent tasks to execute, so it makes the necessary ZooKeeper call and blocks. The asynchronous API, however, enables an application to have both multiple outstanding ZooKeeper operations and other tasks executed in parallel. The ZooKeeper client guarantees that the corresponding callbacks for each operation are invoked in order.
ZooKeeper does not use handles to access znodes. Each request instead includes the full path of the znode being operated on. Not only does this choice simplifies the API (no open() or close() methods), but it also eliminates extra state that the server would need to maintain.
Each of the update methods take an expected version number, which enables the implementation of conditional updates. If the actual version number of the znode does not match the expected version number the update fails with an unexpected version error. If the version number is 1 it does not perform version checking.
Sessions. A client connects to ZooKeeper and initiates a session. Sessions have an associated timeout. ZooKeeper considers a client faulty if it does not receive anything from its session for more than that timeout. It is through this session that ZooKeeper can identify clients in fulfilling the FIFO order guarantee
With leader managing processes and configuration has two important requirements
- As the new leader starts making changes we do not want other processes to start using the configuration that is being changed; • If the new leader dies before the configuration has been updated we do not want the processes to use this partial configuration.
With ZooKeeper, the new leader can designate a path as the ready znode and other processes will only use the configuration when that znode exists. The new leader makes the configuration change by deleting ready, updating the various configuration znodes, and creating ready. All of these changes can be pipelined and issued asynchronously to quickly update the configuration state.
Because of the ordering guarantees, if a process sees the ready znode, it must also see all the configuration changes made by the new leader. If the new leader dies before the ready znode is created then the other processes know that the configuration has not been finalized and do not use it.
What is C1 saw Ready starts sending out reads and a few seconds later C2 sets the flag to not ready for updating the configuration, Now this is why we use watches which sends you a timely notification when this goes down
Zookeeper can be used to implement powerful primitives without knowing about them by clients using the ZooKeeper client API. Some common primitives such as group membership and configuration management are also wait-free. For others, such as rendezvous, clients need to wait for an event. Even though ZooKeeper is wait-free, we can implement efficient blocking primitives with ZooKeeper. ZooKeeper’s ordering guarantees allow efficient reasoning about system state, and watches allow for efficient waiting.
Configuration management
To implement dynamic configuration management with ZooKeeper, we can store configuration in a znode, zc. When a process is started, it starts up with the full pathname of zc. The process can get its required configuration by reading zc and setting the watch flag to true. It will get notified whenever the configuration changes, and can then read the new configuration with the watch flag set to true again.
Rendezvous
rendezvous meaning stackoverflow
Let’s consider a scenario where a client wants to start a master process and many worker processes, with the job of starting the processes being handled by a scheduler. The worker processes will need information about the address and port of the master to connect to it. However, because a scheduler starts the processes, the client will not know the master’s port and address ahead of time for it to give to the workers.
We handle this scenario with ZooKeeper using a rendezvous znode, Zr , which is an node created by the client. The client passes the full pathname of Zr as a startup parameter of the master and worker processes. When the master starts it fills in Zr with information about addresses and ports it is using. When workers start, they read Zr with watch set to true. If Zr
has not been filled in yet, the worker waits to be notified when Zr is updated. If Zr is an ephemeral node, master
and worker processes can watch for Zr to be deleted and clean themselves up when the client ends.
Group Membership
As described in an earlier section, we can use ZooKeeper to implement group membership by creating a znode zg to represent the group. Any process member of the group can create an ephemeral child znode with a unique name under zg using the SEQUENTIAL flag. The znode representing a process will be automatically removed when the process fails or ends.
A process can obtain other information about the other members of its group by listing the children under zg. It can then monitor changes in group membership by setting the watch flag to true.
Queues
Distributed queues are a common data structure. To implement a distributed queue in ZooKeeper, first designate a znode to hold the queue, the queue node. The distributed clients put something into the queue by calling create() with a pathname ending in “queue-“, with the sequence and ephemeral flags in the create() call set to true. Because the sequence flag is set, the new pathnames will have the form path-to-queue-node/queue-X, where X is a monotonic increasing number. A client that wants to be removed from the queue calls ZooKeeper’s getChildren( ) function, with watch set to true on the queue node, and begins processing nodes with the lowest number. The client does not need to issue another getChildren( ) until it exhausts the list obtained from the first getChildren( ) call. If there are are no children in the queue node, the reader waits for a watch notification to check the queue again
To implement a priority queue you need only make two simple changes to the generic queue recipe . First, to add to a queue, the pathname ends with “queue-YY” where YY is the priority of the element with lower numbers representing higher priority (just like UNIX). Second, when removing from the queue, a client uses an up-to-date children list meaning that the client will invalidate previously obtained children lists if a watch notification triggers for the queue node.
Simple Locks
The simplest lock implementation uses lock files. The lock is represented by a znode. To acquire a lock, a client tries to create the designated znode with the EPHEMERAL flag. If the create succeeds, the client holds the lock. Otherwise, the client can read the znode with the watch flag set to be notified if the current leader dies. A client releases the lock when it dies or explicitly deletes the znode. Other clients that are waiting for a lock try again to acquire a lock once they observe the znode being deleted.
This suffers from the herd effect. That is if there are many clients waiting to acquire a lock even tho only one client can acquire the lock. We solve this by lining up clients requesting the lock using the SEQUENTIAL flag and each client obtains the lock in order of request arrival and by only watching the znode that precedes the client’s znode, we avoid the herd effect by only waking up one process when a lock is released or a lock request is abandoned.
Write Lock
1 n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 2
Read Lock
1 n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 3
Double Barrier
Double barriers enable clients to synchronize the beginning and the end of a computation. When enough processes have joined the barrier, processes start their computation and leave the barrier once they have finished
A barrier in ZooKeeper is a znode called b. Every process p registers with b by creating a znode as a child of b – on entry, and unregisters – removes the child – when it is ready to leave.. We use watches to efficiently wait for enter and exit conditions to be satisfied. To enter, processes watch for the existence of a ready child of b that will be created by the process that causes the number of children to exceed the barrier threshold. To leave, processes watch for a particular child to disappear and only check the exit condition once that znode has been removed.
Implementation
ZooKeeper provides high availability by replicating the ZooKeeper data on each server that composes the ser- vice. We assume that servers fail by crashing, and such faulty servers may later recover. The figure below shows the high- level components of the ZooKeeper service. Upon receiving a request, a server prepares it for execution (re- quest processor). If such a request requires coordination among the servers (write requests), then they use an agreement protocol (an implementation of atomic broadcast), and finally servers commit changes to the Zoo- Keeper database fully replicated across all servers of the ensemble. In the case of read requests, a server simply reads the state of the local database and generates a response to the request.
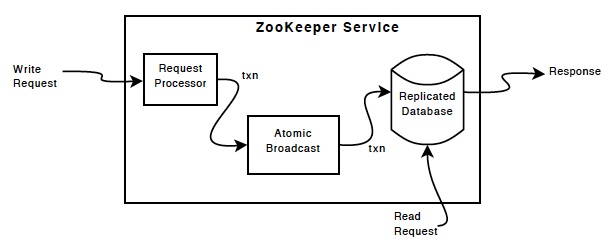
Request Processor converts client requests to transactions which unlike client requests are idempotent. When the leader receives a write request, it calculates what the state of the system will be when the write is applied and transforms it
into a transaction that captures this new state, eg: if a client does a conditional
setData and the version number in the request matches
the future version number of the znode being updated,
the service generates a setDataTXN that contains the
new data, the new version number, and updated time
stamps. If an error occurs, such as mismatched version
numbers or the znode to be updated does not exist, an
errorTXN is generated instead.
Atomic Broadcast is achieved using Zab which uses by default a simple majority quorums to decide on a proposal and thus ZooKeeper can only work if a majority of servers are correct (i.e., with 2f + 1 server we can tolerate f failures). Zab provides stronger order guarantees than regular atomic broadcast. More specifically, Zab guarantees that changes broadcast by a leader are delivered in the order they were sent and all changes from previous leaders are delivered to an established leader before it broadcasts its own changes.
Replicated Database is an in-memory database containing the entire data tree which is used when the server recovers from a crash. We call ZooKeeper snapshots fuzzy snapshots since we do not lock the ZooKeeper state to take the snapshot; instead, we do a depth first scan of the tree atomically reading each znode’s data and meta-data and writing them to disk. Since the resulting fuzzy snapshot may have applied some subset of the state changes delivered during the generation of the snapshot, this can cause reapplying transactions which however will not an issue cause they be idempotent and works as long as we apply the state changes in order.
Conclusion
ZooKeeper takes a wait-free approach to the problem of coordinating processes in distributed systems, by exposing wait-free objects to clients.ZooKeeper achieves throughput values of hundreds of thousands of operations per second for read-dominant workloads by using fast reads with watches, both of which served by local replicas. Although our consistency guarantees for reads and watches appear to be weak, we have shown with our use cases that this combination allows us to implement efficient and sophisticated coordination protocols at the client even though reads are not precedence-ordered and the implementation of data objects is wait-free. The wait-free property has proved to be essential for high performance.
Links and FAQ
Q: One use of Zookeeper is as a fault-tolerant lock service. Why isn’t possible for two clients to acquire the same lock? In particular, how does Zookeeper decide if a client has failed and it can give the client’s locks to other clients?
Zookeeper gives the client’s locks to other clients if the client releases the lock when it dies or explicitly deletes the znode